Tesseract Win32 VC++ Rebuild Tutorial
Tesseract OCR 原本是 HP 實驗室所發展的 OCR 引擎,2006 年釋出為開放原始碼專案,目前由 Google 維護發展。
這兩天因為有某專案需要使用文字辨識功能,原本打算使用 PHP 進行,不過效率不彰,所以投奔到 Tesseract 的懷抱,但是原始檔案中缺少 libtiff 的支援,這時候就需要自己動手編譯了。
所需軟體
步驟
下載 Tiff for Windows Complete package, except sources 並安裝。
開啟 tesseract.sln 專案
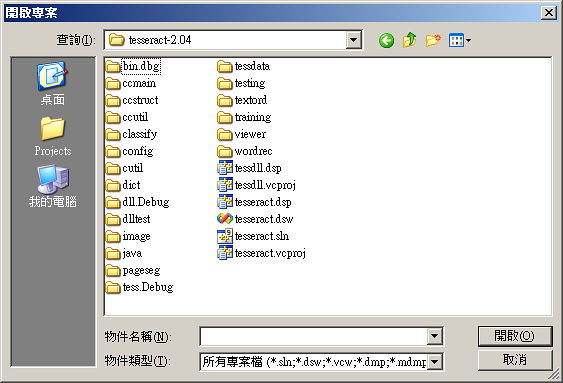
點選「工具 » 選項 » 專案和方案 » VC++ 目錄」右側的顯示目錄分別新增 Include 及 程式庫檔 並個別指向 Tiff for Windows 的 Include 及 Lib 資料夾。
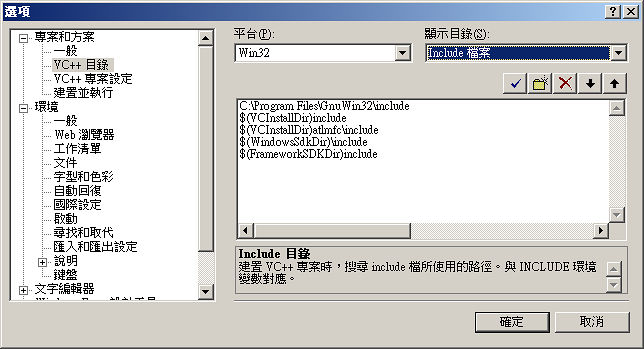
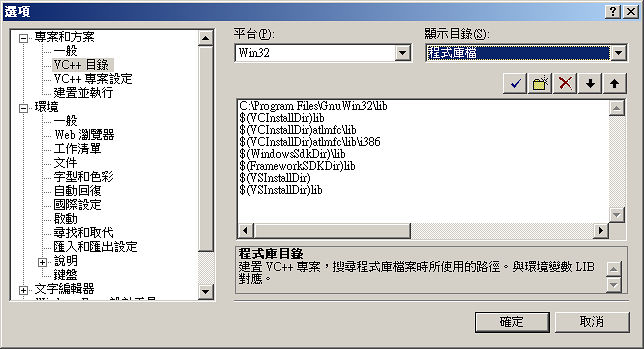
在左側「方案總管」中,針對每個專案點選右鍵選擇「屬性 » 組態屬性 » C/C++ » 前置處理器」,右側的「前置處理器定義」加上 HAVE_LIBTIFF。
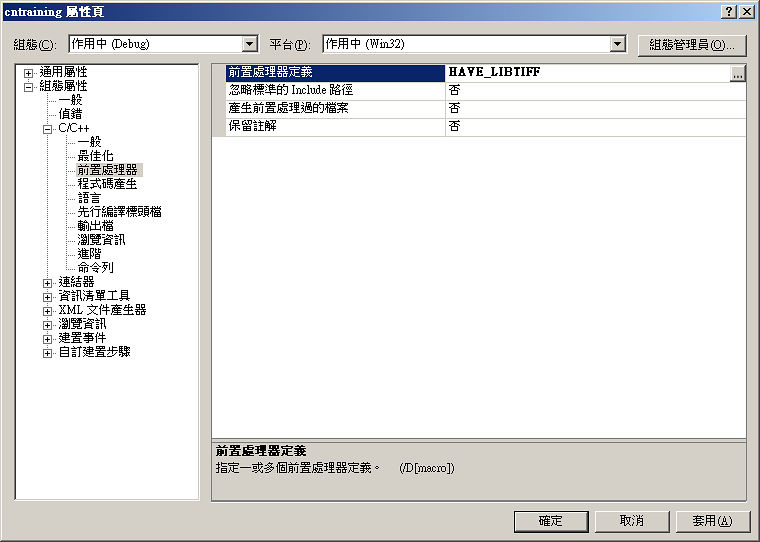
接著在「屬性 » 組態屬性 » 連接器 » 輸入」,右側的「其他相依性」加上 libtiff.lib。
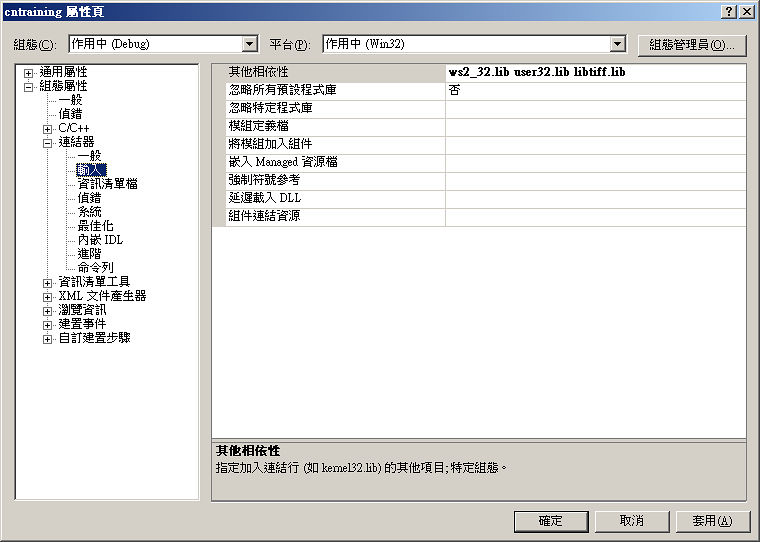
設置完成後即可進行建置編譯。
這裡也有我編譯好的版本下載:Tesseract 2.04 Win32 Rebuild(2.40 MB)
SHA256: 02ade58c75542b5a69b13c9932ae8d921656bfb86fd839ec806a2022d48c24e0
內含:bbTesseract 可編輯學習檔、tessdata English、tessconfig
問題
Q: 執行 tesseract.exe 會提示「找不到 jpeg62.dll」
A: 將 C:\Program Files\GNUWin32\bin\jpeg62.dll 複製到 tesseract 目錄
Q: 執行 tesseract.exe 會提示「找不到 zlib1.dll」
A: 將 C:\Program Files\GNUWin32\bin\zlib1.dll 複製到 tesseract 目錄
延伸閱讀:
洪健齡
says:大大您好,請問 可以自己訓練tesseract-ocr 樣本嗎? BOX檔? 感謝您!~!
essoduke
says:當然可以啊,手動步驟如下:
1.建立 BOX:
tesseract pic.tif pic batch.nochop makebox
2.分析 BOX:
tesseract pic.tif junk nobatch box.train
3.產生訓練檔:
training\mftraining ..\pic.tr
4.合併:
training\cntraining ..\pic.tr
5.解析 Unicode:
training\unicharset_extractor ..\pic.box
6.將產生的四個資料檔複製到 tessdata:
tessdata/eng.inttemp
tessdata/eng.normproto
tessdata/eng.pffmtable
tessdata/eng.unicharset
可以參考 Tesseract Wiki 或:
http://www.win.tue.nl/~aeb/linux/ocr/tesseract.html
http://hi.baidu.com/sinomazing/blog/item/098e6f879dc05922c75cc372.html
洪健齡
says:大大您好:
非常感謝您的熱心回覆!!!感激不盡…
抱歉呀~有個問題 想要跟您請教請教…
我是想要用這個來OCR 汽車車牌
我把車牌剪下來 拿進去訓練
步驟都和http://hi.baidu.com/sinomazing/blog/item/098e6f879dc05922c75cc372.html
一樣
我是用三個車牌0125-GF.tif, 4567-ML.tif, 7107-FR.tif
產生了三個box(0125.box,4567.box,7107.box)
並且進行”tesseract scan.tif junk nobatch box.train”; 生成三個訓練檔文件*.tr(0125.tr,4567.tr,7107.tr)
然後Clustering 把三個tr檔給串在一起
進行”mftraining 0125.tr 4567.tr 7107.tr”; 生成文件”inttemp”, “pffmtable” and “Microfeat”(Not used)
進行”cnTraining 0125.tr 4567.tr 7107.tr”;生成文件”normproto”;
接著 進行”unicharset_extractor 0125.box 4567.box 7107.box”; 生成文件”unicharset”
Dictionary Data
接著Create two UTF-8 text file, “frequent_words_list” and “words_list”, the words in the files should not be duplicated;
Run “wordlist2dawg frequent_words_list freq-dawg”
Run “wordlist2dawg words_list word-dawg”;
This will generate two files, “freq-dawg” and “word-dawg”;
接著有一點點不太懂 7.Putting it all together
All you need to do now is collect together all 8 files and rename
them with a lang. prefix;
File “eng.DangAmbigs” and “eng.user-words” could be empty;
If create “eng.DangAmbigs” file, the characters must be exist in the
“scan.box”;
他是說我們直接拿原來預設的”eng.DangAmbigs” and “eng.user-words”和我們車牌訓練產生的六個 結合成八個
放在一起嗎? 那”eng.DangAmbigs” and “eng.user-words”檔案要空的嗎? 還是用預設的呢? 或是要自己建呢?
我是試過用原本內建的”eng.DangAmbigs” and “eng.user-words 然後其他六個改成我的 或是”eng.DangAmbigs” and “eng.user-words清成空的 加上我的那六個
這八個檔案一起放在testdata中 去執行第八步驟
8. Try it
Run “tesseract scan.tif output -l eng”
The file “output.txt” is the result;
最後卻產生如下的錯誤訊息
Error: 11 classes in inttemp while unicharset contains 14 unichars.
一開始訓練一個車牌(4567-ML)時的錯誤訊息是:
Error: 4 classes in inttemp while unicharset contains 8 unichars
後來再加一個車牌(0125-GF)產生的錯誤訊息是:
Error: 10 classes in inttemp while unicharset contains 13 unichars.
很長的問題!! 成心希望essoduke大 能幫忙回覆,萬分感恩呀~
我的MSN是[email protected]
如需任何幫忙… 也煩請吩咐~! 敬上!!新年快樂!!!~~~~~~~:)
洪健齡
says:誠心
洪健齡
says:Error: X classes in inttemp while unicharset contains Y unichars.
(Where Y != X) There are 2 possibilities: X ~= Y, usually with X 0x56 0x78 0x12 0x13 or similar) will NOT work. Get a sensible hardware architecture, or retrain yourself. Then your inttemp will match the hardware.
essoduke
says:我訓練的方式是把所有字元組合成一張圖檔,所以步驟和您不太一樣 :D
您有使用過 bbTesseract 編輯過您產生的訓練檔嗎?
修正一下看看,可能包含了錯誤的字元
—
您也可以試著略過字典檔,畢竟車牌只是單純的英數字元。
洪健齡
says:bbTesseract 我有用來修正BOX
不知道您有沒有來訓練車牌呢?
非常感謝!!
Error: 10 classes in inttemp while unicharset contains 13 unichars.
這個錯誤是什麼原因呢?
洪健齡
says:大大您好:
非常感謝您的熱心回覆!!!感激不盡…
抱歉呀~有個問題 想要跟您請教請教…
我是想要用這個來OCR 汽車車牌
我把車牌剪下來 拿進去訓練
步驟都和http://hi.baidu.com/sinomazing/blog/item/098e6f879dc05922c75cc372.html
一樣
我是用三個車牌0125-GF.tif, 4567-ML.tif, 7107-FR.tif
產生了三個box(0125.box,4567.box,7107.box)
並且進行』tesseract scan.tif junk nobatch box.train』; 生成三個訓練檔文件*.tr(0125.tr,4567.tr,7107.tr)
然後Clustering 把三個tr檔給串在一起
進行』mftraining 0125.tr 4567.tr 7107.tr』; 生成文件』inttemp』, 『pffmtable』 and 『Microfeat』(Not used)
進行』cnTraining 0125.tr 4567.tr 7107.tr』;生成文件』normproto』;
接著 進行』unicharset_extractor 0125.box 4567.box 7107.box』; 生成文件』unicharset』
Dictionary Data
接著Create two UTF-8 text file, 『frequent_words_list』 and 『words_list』, the words in the files should not be duplicated;
Run 『wordlist2dawg frequent_words_list freq-dawg』
Run 『wordlist2dawg words_list word-dawg』;
This will generate two files, 『freq-dawg』 and 『word-dawg』;
接著有一點點不太懂 7.Putting it all together
All you need to do now is collect together all 8 files and rename
them with a lang. prefix;
File 『eng.DangAmbigs』 and 『eng.user-words』 could be empty;
If create 『eng.DangAmbigs』 file, the characters must be exist in the
『scan.box』;
他是說我們直接拿原來預設的』eng.DangAmbigs』 and 『eng.user-words』和我們車牌訓練產生的六個 結合成八個
放在一起嗎? 那』eng.DangAmbigs』 and 『eng.user-words』檔案要空的嗎? 還是用預設的呢? 或是要自己建呢?
我是試過用原本內建的』eng.DangAmbigs』 and 『eng.user-words 然後其他六個改成我的 或是』eng.DangAmbigs』 and 『eng.user-words清成空的 加上我的那六個
這八個檔案一起放在testdata中 去執行第八步驟
8. Try it
Run 『tesseract scan.tif output -l eng』
The file 『output.txt』 is the result;
最後卻產生如下的錯誤訊息
Error: 11 classes in inttemp while unicharset contains 14 unichars.(4567-ML 0125-GF 7107-FR)
一開始訓練一個車牌(4567-ML)時的錯誤訊息是:
Error: 4 classes in inttemp while unicharset contains 8 unichars
後來再加一個車牌(4567-ML 0125-GF)產生的錯誤訊息是:
Error: 10 classes in inttemp while unicharset contains 13 unichars.
很長的問題! 成心希望essoduke大 能幫忙回覆,萬分感恩呀~
我的MSN是[email protected]
如需任何幫忙…也煩請吩咐~! 敬上!!新年快樂!!!~~~~~~~:)
essoduke
says:就錯誤訊息來看,應該是 inttemp 含有 錯誤的 Unicode 字元。
如果使用 bbTesseract 編輯過訓練檔,那應該是 UTF-8 格式沒錯,或是再使用 notepad++、PsPad 等編輯軟體將 BOX 再轉為 UTF-8 試試?
您也可以將車牌圖檔 email 給我,我幫您測試看看
essoduke [at] gmail [dot] com
※Tesseract 目前對於單色圖檔比較有效果
Tesseract Win32 VC++ Rebuild Tutorial | 資訊與工作
says:[…] Tesseract Win32 VC++ Rebuild Tutorial – essoduke’s blog […]